

C++ Where integer read turns into a function call
Looking at compute-intensive languages like OpenCL, that targets modern GPUs among others, one can observe that the most local (private or thread / work-item local) memory is the fastest and the more general it is the slower memory access gets.
The C++ Reality
Eventually one may find thread_local specifier in C++ and think in a following way:
A thread is an atomic unit of computing on CPU too! Maybe there will be gains there as well!
Hell no! It’s quite the opposite! The difference is of course the result of vastly different architectures.
Let’s dive into it and see why GCC with compiler flags set to -O3, generates three call instructions for the code snippet below:
extern thread_local int a;
int main() {
return a ? a = a - 2: 0;
}
To begin with, let’s get on the same page. In the snippet above, the only thing that may need clarification is the thread_local. It's a storage duration specifier like static or auto (e.g. block scope). What it means, is that each thread should have its own copy of the variable. In other words each thread should have an allocated chunk of memory that would be available as soon as a thread is created and eventually destroyed with it. This is of course true for globally scoped thread_local variables as any locally scoped non-static variables are thread_local by definition. In this article I’d like to focus on ELF standard implementation of thread_locals.
The Concept
To create a thread local variable, we need to mix two worlds with each other: the operating system (threads) and the programming language (variables). While some operating systems have APIs providing TLS (Thread Local Storage), C++ implementation of thread_local is OS independent. When it comes to APIs, the OS provides the variable. If the language itself provides it, the OS doesn't know (and doesn’t want to know) anything about the program's variables. Programs are kind of big kids that should be capable of handling their own toys, shouldn’t they?
Fair enough, but that leaves the C++ to deal with it on its own. What is hard about it, though?? The short answer is dynamic linking. Let’s take a step backwards and get back to fundamentals. The concept solution is simple. Let each program have a list of TLS variables. Grouped together with paddings, alignments and what not, they can be called an initialization image - every time a thread starts this image has to be copied somewhere for that thread to operate on.
The Problem
Wait a minute?! Haven’t I said that the problem lies within linking? Why couldn’t a dynamic loader check for such a list in every library needed and compose a final image for all threads to copy? Well, that would be very wasteful (let’s leave aside the problem of how to know if a thread was created to invoke the copying in the first place).
Let’s say a program runs tens of thousands of threads, which is quite a popular use case in server applications. Assuming that most of them handle client connections and they don’t care about thread locals used in other modules, if each of those threads has a complete copy of the image, most of the space (and time allocating it) is wasted.
Are all threads in need of accessing all TLS variables? Are they even aware of them? Not at all. Furthermore, there are better ways to do inter-module communication, so it’s safe to assume that even if some inter-module access to thread locals may occur (e.g. via callbacks), it should be rare.
That leads us to a better solution - a lazy one. Let’s check if a variable is ready at the exact moment of accessing it. By default, no thread_locals exist. They are initialized only when they are being accessed. No cost on you if no access occurs. No need to pay for others’ thread locals. Pay for what you use, when you actually use it. What is more, it also solves the problem with hooking into the moment of thread creation.
Naive Implementation
Proceeding with such a lazy solution, we would need to go through several steps to access the variable, but we’ll get there. First, let’s create an array per thread, containing memory addresses of a particular module’s variables, which are both to be lazily initialized.
Lazy initialization can be solved through a simple check for nullptr. If the value is null, call the copy of a given module’s image, initializing all module’s variables for this thread once and at the same time and then save the copied block’s address into the table.
Address of this array (Thread Vector, yet to be dynamic) can be stored in the Thread Control Block (TCB). Given that the loader would put a number to each module (serving as an index in the array) and the module could access that, it solves the problem.
Array (TV) can be found through address in TCB, indexed by module id and at this index, there’s a pointer to memory with thread_locals. Simple offset there and bingo! We got to a particular thread_local variable.
However there’s another problem waiting just around the corner. Dynamic loading strikes again! Libraries can be loaded at runtime via dlopen() call. Quite often actually - even glibc does that to handle some parts of networking. Those loaded libraries can load other libraries and all of them can have TLS variables. How do running threads with already initialized memory for TLS handle other libs thread locals? Is the size of our array sufficient? How should other libs interact with already loaded modules' variables?
For sure, the size of our array can and will have to change during runtime. This may affect already running threads with already initialized TLS. Also, libraries could be loaded and unloaded so many times through wild patterns, that fragmentation of our array can become an issue.
How is it achieved in ELF?
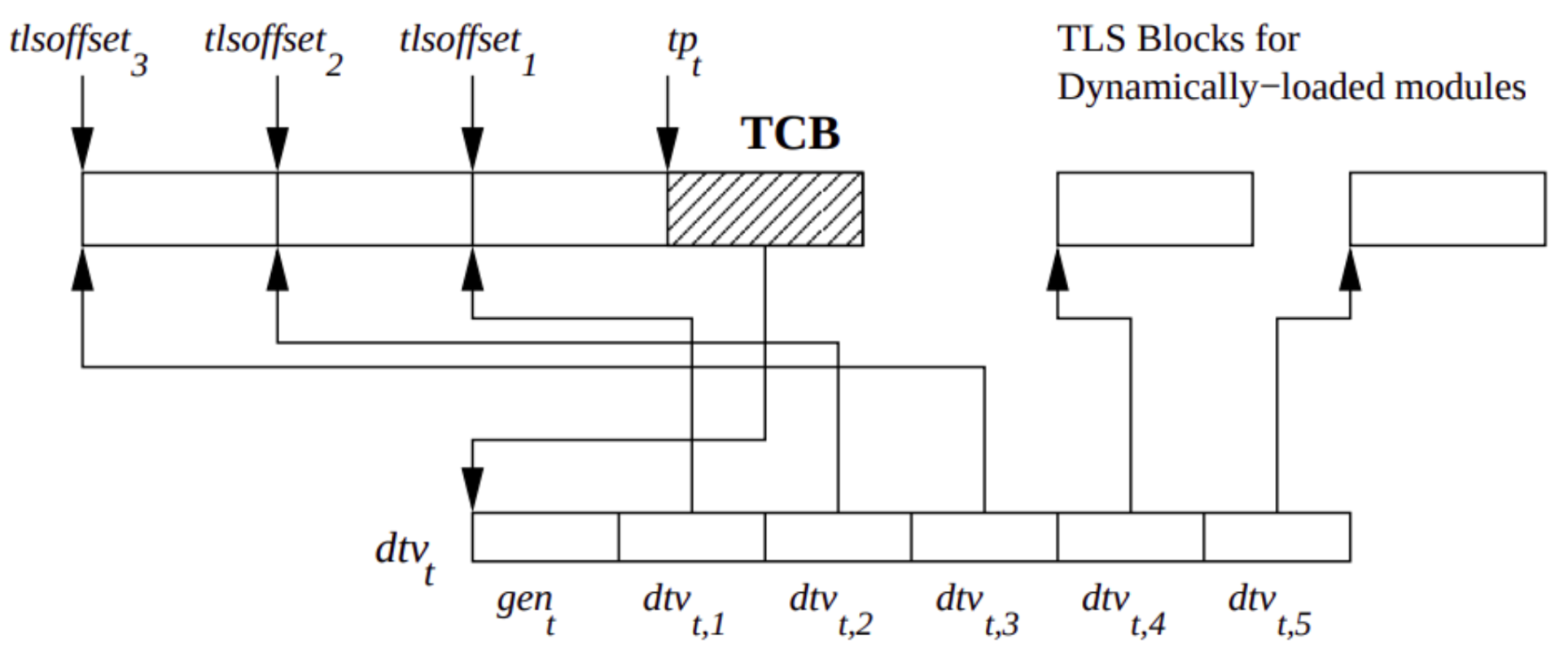
The core concept remains the same - there’s a pointer in the Thread Control Block to an array with pointers to TLS memory regions, but the first element of that array is a version indicator. When accessed, the version is checked. If there is a need to reallocate the arrays (because of extensive dlopen calls for example) version mismatch will ensure a sync (realloc of the array) to account for latest developments in TLS space. Array is resized, but old TLS blocks remain intact and pointers to them are copied to the new array. Voila!!
It’s simple, but clever. Because of the lazy nature and access check performed every time, there’s no need to pause all the threads to update their arrays during each dlopen() call. They will update once they need TLS again, which doesn’t need to happen at all.
What does it look like in real life, you may ask? The snippet we introduced at the beginning compiles to such asm via gcc 14.2 -O3:
extern thread_local int a;
int main() {
return a ? a = a - 2: 0;
}
main:
push r12
mov r12d, OFFSET FLAT:TLS init function for a
push rbp
push rbx
test r12, r12
je .L2
call TLS init function for a
.L2:
mov rbp, QWORD PTR a@gottpoff[rip]
mov ebx, DWORD PTR fs:[rbp+0]
test ebx, ebx
je .L1
test r12, r12
je .L4
call TLS init function for a
.L4:
mov eax, DWORD PTR fs:[rbp+0]
lea ebx, [rax-2]
test r12, r12
je .L5
call TLS init function for a
.L5:
mov DWORD PTR fs:[rbp+0], ebx
.L1:
mov eax, ebx
pop rbx
pop rbp
pop r12
ret
I wanted to keep the example simple so here we get somewhat of an optimized version. There are three calls to TLS initialization, preceded by “already initialized” tests. The rest is just handling the value calculation. There are three calls for three accesses to a variable:
- First: read (in the condition)
- Second: read (to get value ‘a-2’)
- Third: write again into a
Possible Optimizations
Due to the check in lazy initialization, only one call is executed, but it doesn’t always need to be like that. We may have a scenario, where there won’t be any calls at all, or the check won’t get inlined resulting in more calls. Compilers try their best to optimize the code depending on factors like:
- Availability outside of the compilation unit
- Presence in modules available from the program start
- Access model (not covered in this article)
Based on the above, they will pick one or another optimization to apply. Linker can change the code here too, but to be fair though, there’s not much compiler/linker does to TLS apart from selecting the model to be used. One can try to workaround subsequent calls / initialization checks by getting a pointer to the TLS variable and accessing the variable directly to avoid overhead, but in my opinion if it gets to such a point, it’s worth reconsidering the whole idea that led to that point initially.
Summary
What I covered in this blog post is of course a simplification. I omitted a couple nuances, but I wanted to bring into light the challenges that make TLS more complicated than it looks like at first glance. Turns out it’s a pretty loader-heavy feature. When I saw TLS for the first time, I thought it was a cool performance feature. Oh boy, how much was I mistaken…


