

The unexpected cost of shared pointers
A bit of background
Those who've read our first blog post know that at Oxla, we are committed to identifying and fixing even the smallest inefficiencies to improve performance. We recently profiled a query's cold run and discovered an unexpected issue – memset calls consuming a significant fraction of CPU time.
Before revealing more, we must delve into the internal workings of Oxla to help you understand the cause behind this observation. Oxla utilizes distributed object storage, such as S3, to store data. As a result, we cannot rely on the file system caching provided by the operating system unless we first copy the data to local storage.
We decided against making local copies of files because:
- It adds an additional delay between loading the data and making it available.
- Requires local storage, which is not that cheap: Elastic Block Storage is ~3x more expensive than S3 on AWS.
- Requires copying data between kernel space and user space.
What has happened
So, going back to our profiling, that’s what we have observed:
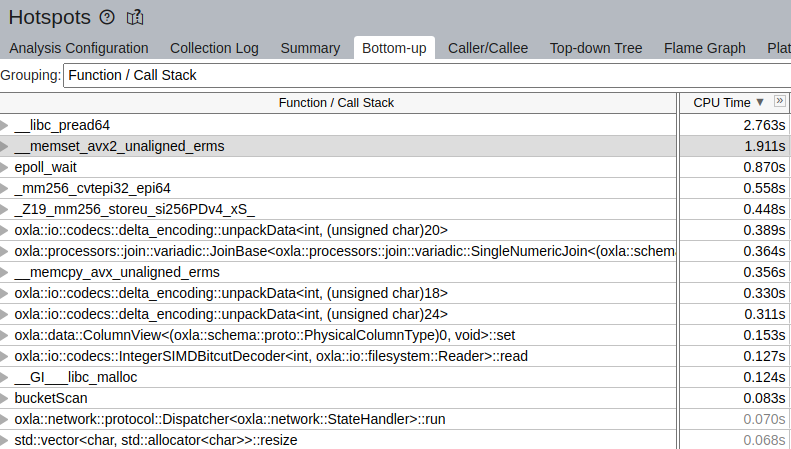
This resulted in terrible CPU usage:

A quick analysis led to the conclusion that code calling memset is here:
auto line = std::make_shared<Line>();And now, let’s check the Line struct definition:
static constexpr std::size_t kLineSize = (1 << 23); // 8MB
struct Line {
char _data[kLineSize];
std::mutex _mtx;
std::atomic<std::size_t> _size = 0;
};This is a simple structure without an explicit constructor. _data field is not initialized during allocation: this is filled later after we receive data from storage. _mtx and _size are not using memset in their constructors. Following the age-old internet wisdom of "Google it," I decided to do just that. Here's what I found: std::make_shared is setting the whole structure to 0 if no default constructor is provided.
After adding the following constructor to the struct:
Line() {}Profiling results were completely different:
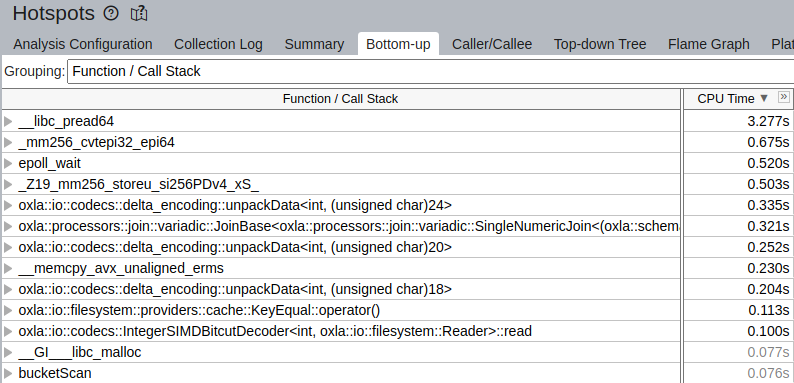
And here we have much better CPU usage:

The issue seems to be resolved in C++20 by the function std::make_shared_for_overwrite.
But is it important for you?
Most probably, it is not. Usually, objects allocated this way are small: tens of bytes, hundreds at most. Also, it is typical that object is used immediately after being allocated. The most time-consuming part of initializing an object is usually not calculating the values to store but pulling existing content of cache lines it belongs to from RAM to CPU cache. After it is done, subsequent writes are much faster – as long as the object fits nicely into the cache.
This means that memset is doing the most challenging part of the work: loading data from RAM into the cache. Subsequent actual initialization is much faster.
Let’s measure it. We will start by defining the following simple types:
template <size_t N>
struct Object {
char data[N];
};
template <size_t N>
struct ObjectWithConstructor {
char data[N];
ObjectWithConstructor() {}
};Some constants:
constexpr size_t total_size = 500000000; // total size of allocations: 0.5GB
constexpr size_t size_small = 100; // small allocation size, simulated typical allocation
constexpr size_t small_allocations_num = total_size / size_small;
constexpr size_t size_large = 100000000; // large allocation, that does not fit into cache, 100MB
constexpr size_t large_allocations_num = total_size / size_large;Let’s consider that it allocates an object using make_shared without using it:
template <typename T>
void testWithoutInit(const size_t repeats) {
std::vector<std::shared_ptr<T>>& objs =
*(new std::vector<std::shared_ptr<T>>); // There is memory leak here but we are sure that we get fresh part of
// memory
objs.reserve(repeats);
for (size_t i = 0; i < repeats; ++i) {
auto obj = std::make_shared<T>();
objs.template emplace_back(std::move(obj));
}
}Calling testWithoutInit<Object<size_small>>(small_allocations_num); takes 0.452447s
Calling testWithoutInit<Object<size_large>>(large_allocations_num); takes 0.104688s
Clearly, the run time depends mostly not on the amount of data cleared but on the number of allocations in the case of small objects.
What if there is a constructor?
Calling testWithoutInit<ObjectWithConstructor<size_small>>(small_allocations_num); takes 0.444047s
Calling testWithoutInit<ObjectWithConstructor<size_large>>(large_allocations_num); takes 1.051e-05s
Not much has changed for small objects. On the other hand, calling it for a large object is now super fast: this code is effectively calling malloc 100 times.
Now let’s consider a more realistic case: first, we allocate an object, and then we write something to it:
template <typename T>
void testWithInit(const size_t repeats, const size_t size) {
std::vector<std::shared_ptr<T>>& objs = *(new std::vector<std::shared_ptr<T>>);
objs.reserve(repeats);
for (size_t i = 0; i < repeats; ++i) {
auto obj = std::make_shared<T>();
char* data = obj->data;
memset(data, 0, size);
objs.template emplace_back(std::move(obj));
}
}.png)
For small objects having a constructor or not having it does not matter that much: a variant with a constructor is ~7% faster, but for large objects difference is ~19%.
But that’s not all. Let’s create a multithreaded version of our test with initialization:
template <typename T>
std::chrono::duration<double> testWithInitMulti(const size_t repeats, const size_t size) {
std::condition_variable_any cv;
std::vector<std::thread> threads;
std::shared_mutex mtx;
for (size_t i = 0; i < std::thread::hardware_concurrency(); ++i) {
threads.emplace_back([&cv, &mtx, repeats, size]() {
std::shared_lock lock(mtx);
cv.wait(lock, []() { return true; });
testWithInit<T>(repeats, size);
});
}
const std::chrono::time_point<std::chrono::high_resolution_clock> start;
cv.notify_all();
for (auto& thread : threads) thread.join();
auto finish = std::chrono::high_resolution_clock::now();
return finish - start;
}Time for variant without constructor: 0.702222s (testWithInitMulti<Object<size_large>>(large_allocations_num, size_large);)
Time for the variant with a constructor: 0.419979s (testWithInitMulti<ObjectWithConstructor<size_large>>(large_allocations_num, size_large);)
Variant with a constructor is ~40% faster!
What has happened here? Shouldn’t it run at the same speed as the single-thread variant? There is no communication between threads; they are not even sharing memory in a read-only manner.
Unfortunately, there is a resource that every single core of a CPU is sharing: memory channels.
CPU speed has been growing faster than data bandwidth between CPU and RAM for decades. It means that in many cases, when data is processed in parallel, we will observe that processing speed does not scale linearly with the number of cores used.
Because of those limitations, we are very careful about memory transfer in Oxla to deliver our performance. If you want to give us a shot, you can now deploy one cluster node in just 2 minutes. It’s free, so have fun, and let us know your thoughts via hello@oxla.com!
